Actualizado a:7 Febrero de 2018, con el gráfico de la IA Legal en España
Durante el año pasado escribimos ya mucho sobre Legaltech, y mucho más que lo haremos durante este 2018.
Sin embargo, al final es indudable que una imagen vale más que mil palabras. Y una materia como la Legaltech no debe ser ajena a ello. Sobretodo cuando una rama cercana y de la que hablaremos pronto, el Diseño Legal, aboga mucho por la transmisión de conocimiento legal más allá de las palabras.
Por ello comenzamos el año presentando el que esperamos que sea el primero de muchos gráficos de la Legaltech española, europea y quizá mundial. A lo largo del año vamos a transmitir mucho conocimiento sobre Legaltech en palabras, pero algunas materias y cuestiones concretas también deben existir de forma más visual y fácil de comprender quizá.
En este artículo los iremos recopilando y organizando.
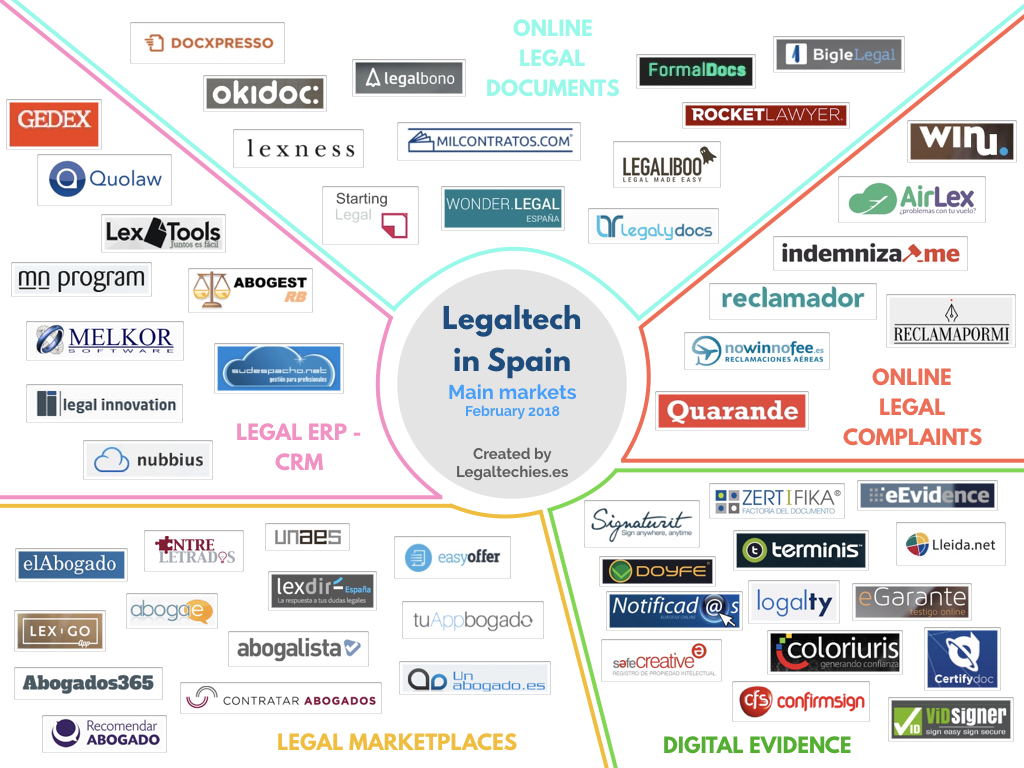
Este primer ejercicio de visualizar la Legaltech española se concreta en algo que ya se ha podido ver en otros mercados, como el alemán o el francés, un compendio de los principales nichos de la Legaltech de cada país de forma visual, mediante los logos de cada empresa y categorizados según el área de actuación.
Nuestro primer gráfico de la Legaltech española, los principales nichos
En el caso español, y según nuestros datos, hay 5 grandes categorías en nuestro mercado: 1) software de gestión para despachos y abogados, 2) plataformas para adquirir y/o generar contratos online, 3) plataformas de intermediación para que los abogados se den a conocer y los clientes encuentren al profesional que necesitan (los llamados marketplaces jurídicos), 4) los servicios para plantear reclamaciones legales de todo tipo desde el sofá de casa mediante Internet y 5) los servicios para recopilar y generar con seguridad evidencias digitales.
La versión de Febrero 2018 suma un servicio en Marketplaces Jurídicos (Entre Letrados), uno en Reclamaciones Online (Reclama por Mí) y dos en Evidencias Digitales (ConfirmSign y Validated ID o Vidsigner).
Si bien la categoría de servicios para responder consultas online es grande y en el post original hablamos de él como uno de los grandes nichos, es verdad que cada vez es más difícil separar esa categoría de los marketplaces jurídicos (que de forma habitual incluyen esa función también en sus servicios). Además, en el último año han desaparecido algunos de los servicios que estaban completamente centrados en la materia de las consultas legales online.
Por todo ello se ha preferido destacar la categoría de plataformas para reclamaciones legales online.
By the way, we have an English version too:
Legaltech in Spain, principal markets
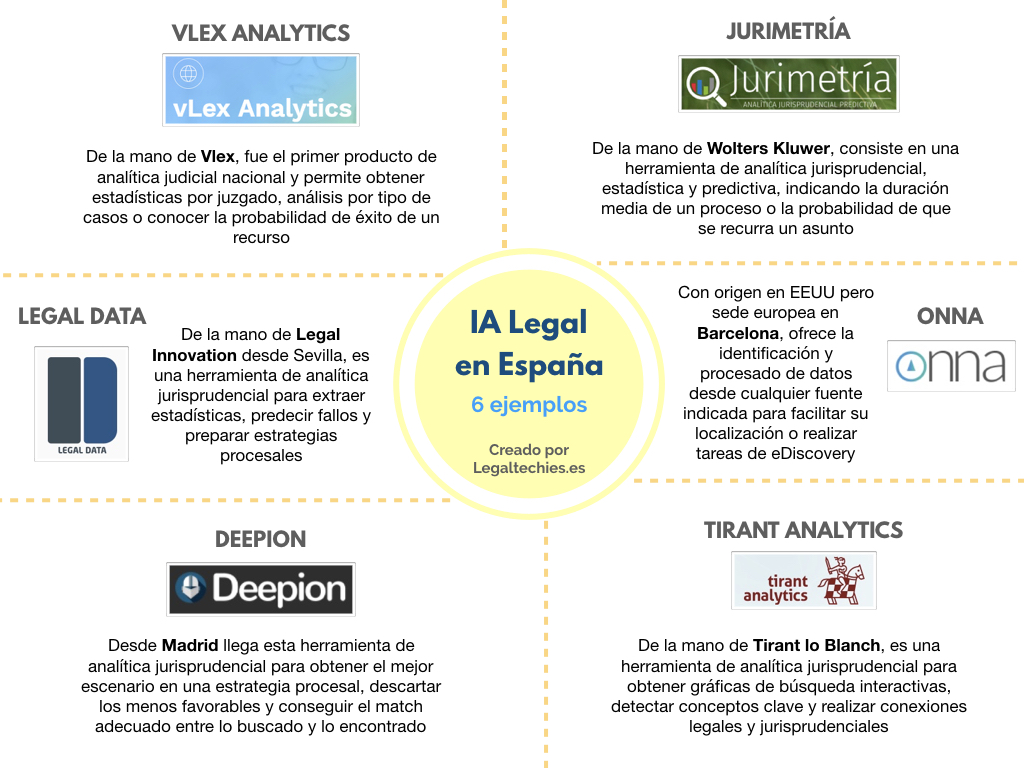
Presentamos un nuevo gráfico relativo a los servicios con origen en España, o un importante vínculo con el territorio, relativos al área de la inteligencia artificial aplicada al sector legal. En este sentido podemos hablar de hasta seis ejemplos, cinco de ellos vinculados a los servicios de analítica jurisprudencial y el restante vinculado con las tareas de e-Discovery o localización y búsqueda de datos. Dichos servicios son: Vlex Analytics, Jurimetría, Tirant Analytics, Legal Data, Deepion y Onna.
Aquí el gráfico:
6 ejemplos de IA Legal con origen en España o importante vínculo al territorio
Pues eso, iremos durante el año compartiendo otros gráficos interesantes y actualizando los ya publicados. Hay mucho por contar y mostrar.
Llega el final de año y eso siempre es buen momento para mirar atrás y hacer balance.
Pero también es una buena ocasión para mirar adelante e intentar avanzarse a algunas de las tendencias, ideas y movimientos que veremos en el nuevo año.
Pues bien, aprovechando que estos días la American Bar Association publicó su lista de 15 proyectos Legaltech seleccionados para su Startup Alley Competition en la 2ª edición del TechShow, que celebrará el próximo 7 a 10 de marzo de 2018, creo que esos proyectos son una buena excusa para mirar un poco hacia delante y ver qué se aproxima en 2018 año en materia Legaltech.
Antes de nada, decir que la mayoría de estos proyectos están pensados para abogados y despachos. Por tanto no es Legaltech a nivel de consumidor, área en la que se están dando otro tipo de novedades y de la que también doy una pincelada.
La lista me parece interesante ya que los proyectos son muy nuevos y no el típico servicio de revisión de contratos, análisis en due dilligence o similar. Por tanto, apuntan ya a áreas mucho más específicas y son iniciativas más diversas.
Por cierto, si alguien tiene curiosidad sobre predicciones en materia de IA Legal, aquí un buen resumen del año y pautas de futuro. En resumen, en 2018 llega la hora de mostrar usos prácticos de la tecnología (que los hay) y abandonar las abstracciones y el hype.
Vamos con ello:
Book- it Legal, o una plataforma web para conectar a abogados y estudiantes de Derecho para encargar tareas por proyecto. Por ejemplo para revisar documentos, investigar una materia o redactar un artículo. Pretende que los abogados puedan recurrir a «mano de obra» más económica a la vez que los estudiantes tienen nuevas y más diversas vías para obtener su primera experiencia y sueldo en el sector. En Europa hay algo parecido con F-Lex. Y de forma similar, Vortex Legal quiere convertirse en el Expedia del Derecho, facilitando la localización y puntuación de cualquier tipo de profesional relacionado con el mundo jurídico (peritos, traductores, intérpretes, detectives y demás).
Gideon, o un asistente legal avanzado que opera a nivel externo e interno. Es decir, puede hacer de primer punto de contacto con un potencial cliente pero a la vez puede servir para informar a un cliente sobre el estado de su caso. Con la mínima intervención humana. Para ello se integran con el CRM de la firma, obteniendo tanta información como sea posible e incluso permite referenciar los clientes que no interesen a la red interna de abogados de la plataforma. Por cierto, tenemos otros asistentes legales en camino en 2018, como Lara o la nueva versión de Larissa.
Time Miner, o un sistema para medir el tiempo de trabajo dedicado pero con la particularidad que solo funciona en móvil. El software monitoriza toda la actividad realizada con clientes y de forma automática, sin tener que hacer nada extra, entrega un informe diario del tiempo dedicado a escribir un mail o hacer una llamada. TotemTimer intenta hacer algo así pero a nivel de hardware y Ping dice ser el Fitbit de los abogados. Mientras tanto, Digitory Legal hace el camino al revés, usar machine learning para predecir el coste de una tarea y los plazos a que implicará.
Voluble, o el análisis de datos no estructurados en redes sociales, foros e Internet en general para extraer tendencias y datos útiles en materia legal. Desde ayudar a fundamentar una propuesta en propiedad industrial, a probar un problema de competencia desleal o publicidad engañosa. Social Evidence también analiza contenido en Internet para buscar, localizar y usar información de medios sociales con relevancia legal para un concreto caso. Al igual que Evichat, que hace un «peritaje» de un dispositivo móvil para luego facilitar la localización de información relevante en un asunto. Y en parte relacionado, Loom Analytics también busca trabajar la analítica jurídica en datos no estructurados, en este caso en asuntos que se resolvieron mediante acuerdo extrajudicial pero en los que interesa conocer qué hubiera pasado de haberse llegado a juicio.
Qualmet, o una plataforma SaaS para que departamentos legales de mediana y gran empresa midan y auditen el valor proporcionado por los servicios legales externos que tengan contratados. También en la línea de simplificar y trazar adecuadamente contrataciones muy complejas está SimplyAgree. Y pensando en el abogado unipersonal que quiere automatizar todo lo posible el proceso de redacción de contratos y documentación legal, Lawyaw intenta darle una nueva vuelta de tuerca a la materia aplicando de forma agresiva la detección de errores, duplicidades y demás.
Y antes de acabar, creo que merece mención otra área que también verá el próximo año numerosos proyectos interesantes. Se trata del llamado «Access to Justice» o favorecer el acceso a la Justicia y a servicios legales mediante la tecnología a personas con menos recursos. Un problema muy serio y en el que la tecnología puede ayudar. En ese sentido hay iniciativas llamativas como la de MetaJure (un gestor inteligente de documentos legales) que por cada dólar obtenido en sus rondas de financiación ofrece gratis una cantidad equivalente de sus productos a servicios legales gratuitos, de bajo coste o del turno de oficio. Otro destacable es HelpSelf Legal, un chatbot que ofrece información jurídica básica a víctimas de la violencia de género (en España tenemos a V¡VA haciendo algo similar). Llama también la atención Pro Bono Catalog, una plataforma para dar visibilidad y atender casos pro bono de forma estructurada, geolocalizada y centralizada, o JustFix, un servicio online de ayuda legal gratuito en Nueva York para personas en riesgo de exclusión que necesiten consejo en reclamaciones inmobiliarias o relacionadas con la vivienda.
Y estos serían algunos de los proyectos que veremos durante el año que viene.
Definitivamente no consisten en la típica plataforma de venta de plantillas legales, marketplace jurídico o CRMs al uso, aunque también los hay o son ideas que sirven como punto de partida en algunos casos. Pero para ser proyectos que están dando sus primeros pasos, la apuesta tan fuerte por analítica de datos legales, la aplicación de técnicas complejas como machine learning o NLP que realizan o los enfoques que ofrecen son francamente nuevos y a tener en cuenta.
Y eso que no he mencionado blockchain o contratos inteligentes (aunque ya lo hice hace unos meses), tecnologías que muchas quinielas señalan como una de las que más potencial tendrán en 2018 en materia legal. Sea como sea, si startups legaltech ofrecen ya esto, quién sabe lo que pueden traer durante 2018 los grandes jugadores. Los seguiremos de cerca.
La idea del abogado robot, ese extraño ser capaz de realizar todas las tareas del jurista pero las 24 horas del día y los 7 días de la semana, se ha popularizado mucho en los últimos 12 – 18 meses. De hecho, si alguien seguramente ha colaborado en ese proceso de popularización (aunque de forma involuntaria en buena parte), se trate de ROSS Intelligence.
Conocido como la versión jurídica del sistema de computación cognitiva de IBM, el no menos conocido Watson, ROSS Intelligence (en adelante ROSS) es más que una simple copia jurídica de Watson, pero también menos de lo que en general la prensa generalista (y en ocasiones la jurídica) ha dado a entender.
ROSS opera desde Canadá, que se está posicionando como uno de los centros mundiales en relación al desarrollo de inteligencia artificial, y si bien incluye algunos elementos prestados de Watson, su punto fuerte consiste en un framework de trabajo en materia de IA creado a nivel interno y llamado Legal Cortex.
Logotipo de ROSS Intelligence
¿Pero qué es ROSS exactamente? Pues una herramienta de «legal research» o investigación legal. Es decir, un buscador de jurisprudencia y documentación legal más avanzado que los habituales. Pero además no es aplicable en cualquier materia, ya que ROSS se ha especializado en quiebras y concursos de acreedores.
Ésa es su tarea y es bueno en ella.
Sin embargo, desde por allá 2016, cuando comenzó a operar de forma pública, muchas de las veces que en prensa se hablaba del famoso «abogado robot» era en relación a ROSS. Ahí van unos pocos ejemplos (solo en castellano y sin salir de la página 3 de Google):
Cómo una herramienta que simplemente mejora la búsqueda de jurisprudencia (que no es poca cosa) acaba convirtiéndose en un «abogado de inteligencia artificial» (!) que un bufete contrata (!), es digno de estudio y seguramente un tema que abordaremos próximamente al hablar del mito del abogado robot. Sea como sea, demuestra que a nivel de opinión publicada hay mucho interés en servicios legales automatizados y prestados por máquinas en lugar de personas.
¿Y qué parte del proceso legal automatiza ROSS? En verdad ninguno, ya que el abogado deber ser quien realiza la búsqueda de sentencias o documentación legal aplicable al caso que le ocupa. Ahora bien, las nuevas técnicas que ROSS aplica en esa tarea, mayormente el procesamiento de lenguaje natural y machine learning o aprendizaje automático, aumentan la calidad de los resultados obtenidos y reducen el tiempo invertido en ello.
Vamos a ver esto más detalle.
Según el estudio encargado por ROSS a la consultora Blue Hill Research en enero de este año, cuando se ofreció a 16 abogados probar ROSS junto a Westlaw y LexisNexis (herramientas muy similares pero que usan sistemas de búsqueda más básicos, como las palabras clave o frases concretas), ROSS salió ganando en todos los apartados. Es decir, ROSS demostró ser mejor al reducir el tiempo necesario para obtener resultados útiles, generó resultados de mayor calidad que los otros sistemas de búsqueda e incluso puede ser un generador indirecto de mayor negocio para el cliente (ya que su uso permite invertir las horas ahorradas en otras tareas facturables, acciones de marketing o mejor atención al cliente).
Estudio de Blue Hill Research sobre ROSS en comparación con Wetslaw y LexisNexis
El estudio compara cómo un profesional que trabaje el área de las quiebras o los concursos de acreedores, pero sin llegar a ser un especialista, puede resolver varias dudas sobre la materia que le plantea un cliente. Para resolver esas dudas necesita buscar jurisprudencia que fundamente un determinado argumento, y ahí es donde entran Westlaw, LexisNexis y ROSS.
Las dos primeras herramientas permiten hacer búsquedas booleanas (mediante palabras clave o conectores que busquen conexiones entre términos) o búsquedas con lenguaje natural (cuando se busca una frase, expresión o conjunto de palabras concreto a lo largo de un texto). Por su parte, ROSS aplica el llamado procesamiento de lenguaje natural, algo que como ya explicamos permite que se hagan preguntas de forma natural al sistema y que el software entienda el contexto de los términos o frase a buscar. Por ejemplo, si indico al software que haga una búsqueda sobre «Pagos», que no solo aparezcan los documentos que contienen el término, sino también facturas, presupuestos y otros relacionados que nunca mencionan la palabra «pago» pero el software entiende que están relacionados.
El estudio no es muy largo (11 páginas), puede encontrarse en la web de la compañía y resulta interesante para ver lo mucho que mejora una herramienta de búsqueda de documentación legal al aplicar técnicas modernas. Por ejemplo, en función del número de veces que una sentencia era citada en los ejercicios completados por los 16 abogados, se determinó la relevancia de ese resultado. Entonces se midió en cada herramienta, y según la técnica de búsqueda empleada: 1) el porcentaje de sentencias relevantes que habían sido localizadas; 2) el porcentaje de sentencias relevantes que mostraba el software entre sus primeros 20 resultados; y 3) finalmente el NDCG (donde el máximo es 1) o la similitud entre el posicionamiento de los resultados relevantes en cada programa y el posicionamiento ideal de esos resultados relevantes dada su importancia (es decir, que si las sentencias buenas eran las número 3, 7 y 9, a ver si el software las mostraba en ese orden o en realidad la 9 iba primera y la 3 estaba al final).
La efectividad de ROSS, Westlaw y LexisNexis en sus diferentes sistemas de búsqueda al buscar jurisprudencia relevante
La conclusión es que ROSS gana en todas esas métricas, especialmente cuando se compara con sistema de búsqueda basados en simples palabras clave o conectores. De ese modo, ROSS fue capaz de localizar casi el 56% de las sentencias relevantes, mientras que los sistemas booleanos no llegaban al 32%. El término medio es la búsqueda por expresiones naturales más específicas, que se queda cerca de ROSS pero sin llegar a alcanzarlo (y requiriendo más tiempo para llegar a ese número).
Otras dos métricas que también analiza el informe, pero que simplemente apuntamos, es el tiempo que llevó a cada abogado encontrar la jurisprudencia relevante según el tipo de herramienta usado y el posible beneficio económico que se deriva del uso de ROSS. En ese sentido, encontrar las sentencias relevantes con ROSS llevaba entre 11 y 15 minutos menos que con los otros sistemas. Por tanto, si uno suma todo el tiempo ahorrado al final del año y lo invierte por ejemplo en tareas facturables que antes no podía atender, se podrían ganar de media entre 5.300 y 6.100 dólares más al año (pero ya dice el informe que hay que coger esto un poco con pinzas).
En conclusión, ROSS es una herramienta para buscar jurisprudencia y documentación legal en materia de quiebras y concursos de acreedores (aunque la voluntad es llevarlo a otras materias), solo funciona por ahora con casuística norteamericana y canadiense (no se puede contratar en Europa), consiste en un servicio SaaS y nada tiene que ver con un abogado robot. Es simplemente (y no es poco) una forma más eficaz y rápida de localizar sentencias relevantes en un caso.
Por tanto, ROSS es una buena herramienta para subir un peldaño más en la eficiencia de las tareas legales del día a día. Y un gran ejemplo de lo que irá ocurriendo cada día más en otras áreas y herramientas relacionadas.
¿Deben los abogados aprender a programar? Seguramente esa pregunta haya surgido en más de una ocasión en el área del Derecho más enfocada a la Tecnología. Resultando las opiniones favorables y contrarias.
Si bien el saber no ocupa lugar, personalmente no creo que por defecto todos los abogados necesiten aprender a programar. Ahora bien, entre los abogados que profesionalmente se dedican a cuestiones tecnológicas el debate sí puede tener más lógica. Los motivos para plantearse la necesidad de saber programar a mi parecer son dos:
En primer lugar, una razón más pragmática relacionada con el día a día del abogado tecnológico, que en su tarea quizá necesite entender con precisión cómo se implementa una funcionalidad, qué flujo sigue un dato concreto o la diferencia entre librerías en una auditoría de software. Por tanto en ese contexto la programación puede ser un buen extra.
En segundo lugar, una razón quizá más profunda y cuyo origen sea el muy recomendable libro de Lawrence Lessig, «El Código y Otras Leyes del Ciberespacio». Allí Lessig argumenta, ya en 1999, cómo el código informático (especialmente el de las grandes empresas de Sillicon Valley) es capaz de regular la conducta de un usuario de la misma forma que lo hace el código legal (algo que en 2017 resulta cada vez más evidente). En ese caso, ser capaz de conocer y entender el código informático en detalle casi se convierte en una necesidad para comprender del todo las complejidades técnico-jurídicas a las que nos enfrentamos.
Sea como sea, en ambos casos podría argumentarse que más que saber programar puede resultar necesario tener ciertas nociones de programación que le permitan a uno entender el código, más que escribirlo. Algo así como cuando se aprende un nuevo idioma y sabemos leer en él antes que escribir (y ahí nos quedamos).
Ahora bien, a mi parecer recientemente ha aparecido un nuevo elemento que ha reiniciado el debate y pone mayor énfasis en la necesidad de saber escribir y no solo leer. Me refiero a la aparición de blockchain y el fenómeno de los contratos inteligentes asociados al mismo.
En este caso el argumento consiste en que si los contratos inteligentes son en realidad código informático que permite articular, verificar y ejecutar un acuerdo entre las partes, los abogados que asesoren en la elaboración de esos contratos deberán no solo entender el código, sino también saber escribir en él. De hecho, por ello están naciendo plataformas para contratos inteligentes enfocadas al sector legal. Aunque también es verdad que muchos de esos smart contracts funcionan a través de editores, sin necesidad de picar la línea de código.
En cualquier caso, sea o no buena idea que un abogado comience a programar, si finalmente decide dar el paso adelante, ¿dónde debe acudir? Pues la verdad es que las opciones son muchas, pero lo más curioso es que cada día hay más recursos específicos para abogados que quieren programar.
Comenzando por los recursos más comunes, un abogado podría iniciarse en el mundo de la programación gracias a los cursos ofrecidos en plataformas de formación online como Coursera, Udemy o Khan Academy, entre muchas otras. También pueden encontrarse plataformas de formación online para programadores, como Code Academy, Py o Code.org, entre otras. Sin olvidar las opciones presenciales. Por lo tanto el abanico de opciones aquí es muy amplio.
A su vez, poco a poco van apareciendo más cursos de programación para abogados (aunque también es cierto que mayoritariamente en el mundo anglosajón). Aún así, en España tuvimos uno durante 2016 por parte del FIDE y algunas empresas de consultoría para despachos como Marketingnize los ofrecen ya en sus servicios. En todo caso, es interesante ver que las facultades de Derecho de Harvard, Miami, Georgetown o Chicago-Kent ya ofrecen en sus planes de estudio asignaturas consistentes en programación para abogados.
«Computaional Law» y «Data Analytics» entre las nuevas materias para estudiantes de Derecho
Pero veamos ahora opciones más específicas para juristas (aunque eso sí, en inglés).
Para empezar la iniciativa Coding for Lawyers. Consiste en algo así como un ebook para abogados que quieran aprender a programar. Bastante introductoria, hasta el momento lleva 6 capítulos y pretende enseñar los aspectos más básicos de la programación de forma muy accesible a los abogados.
Por otro lado, había otra iniciativa para enseñar a programar a abogados, llamada Legally Coding, pero desapareció durante 2017 sin caso dar señales de vida.
Finalmente tenemos la mayor particularidad de todas. Proviene de Legalese y consiste en un lenguaje de programación de dominio específico llamado «L4». O lo que es lo mismo, un lenguaje de programación para abogados y con un único propósito, elaborar contratos. Es decir, de la misma forma que R es un lenguaje de programación específico para estadística o SQL es un lenguaje específico para consultas a bases de datos relacionales, Wong Meng Weng y su equipo han creado un lenguaje de programación con un único objetivo: poder elaborar contratos que luego pasan por el correspondiente compilador. Pero en lugar de usar un lenguaje de programación de uso general (como por ejemplo C), han creado uno nuevo pensando en las necesidades propias de un contrato jurídico. Por tanto su idea va mucho más allá de las simples plantillas que muchos de los servicios de autogeneración de documentos legales ofrecen, creando un lenguaje específico para su elaboración que luego simplifique y asegure al máximo su verificación, consistencia o adecuación en un entorno automatizado.
La verdad es que el tema de L4 da para un post en detalle sobre la materia, ya que hay mucha documentación sobre ello y se está generando un interesante movimiento en relación al mismo. Por tanto, volveremos sobre sobre ello. A efectos de este post simplemente nos interesa indicar que existe ya un lenguaje de programación específico para abogados, y quién sabe si en el futuro se acabará convirtiendo en una referencia.
Dicho esto, hasta aquí llega el pequeño resumen de recursos para abogados que quieran aprender a programar. Resulte en el futuro más o menos necesario en general, sí da la sensación que en algunas áreas concretas del Derecho tecnológico puede ser muy útil o incluso imprescindible como habilidad.
Quien quiera iniciarse tiene sin duda opciones más que de sobra. Quizá hoy el mejor camino sea un curso para un lenguaje de programación en general (Python, Javascript o Solidity, por ejemplo). Ahora bien, lo ideal sería hacerlo con un objetivo de tipo legal en mente (crear un chatbot, escrapear contenido legal en Internet o hacer algo de ciencia de datos jurídica). Luego a partir de ahí ir ya avanzando y apuntalando el conocimiento.
Sea como sea, en el medio-largo plazo puede ser una habilidad diferenciadora más que interesante para los abogados tecnológicos. De modo que si hay ganas, ¡a por ello!
Blockchain es seguramente una de las tecnologías más de moda en la actualidad, resultando muy alto el interés y nivel de inversión en proyectos relacionados. Véase como una última muestra el fenómeno de las ICO o Initial Coin Offerings.
Obviamente, el sector legal no es ajeno al universo blockchain. Pero no simplemente a efectos de estudiar las particularidades legales que la tecnología pueda generar, sino a efectos de aplicar soluciones blockchain y sus ventajas en materia legal.
En la actualidad probablemente el campo de los contratos inteligentes o smart contracts sea una de las áreas que mayor interés ha generado en el sector legal respecto a la aplicación de blockchain (por si alguien tiene curiosidad sobre los contratos inteligentes, ya escribí sobre ellos largo y tendido el año pasado).
De hecho, este año han surgido un considerable número de iniciativas blockchain especialmente enfocadas al sector jurídico. Sin embargo, no me refiero con ello a proyectos en los que el papel de los operadores jurídicos puede ser muy importante. Por ejemplo, existen múltiples proyectos relativos a la creación de registros catastrales sobre blockchain.
Su motivación radica en que casi el 70% de la población mundial carece de la posibilidad de acceder a un título de propiedad sobre su tierra. Además, llevar un control de esos títulos es un proceso normalmente muy manual, laborioso y burocrático. Resultando un problema más complejo de lo que parece poner de acuerdo a todas las partes implicadas en cada fase de la transacción de una propiedad, a la vez que se deja constancia registral de fiar de todo ello.
Por ello hay ya en marcha, normalmente todavía en fase de pruebas, proyectos consistentes en crear un registro catastral sobre blockchain en países como Ghana, Suecia, Honduras, Reino Unido, Georgia, Ucrania o Brasil.
Sin embargo, el tipo de proyectos blockchain a los que me refiero están muy enfocados en el sector legal.
Por ejemplo, Agrello es una empresa de Estonia formada por abogados y tecnólogos que ha lanzado una plataforma para la creación de smart contracts. Pero es que además han creado su propio token, llamado DELTA, y con ello lanzaron la primera ICO del sector legal, obteniendo en menos de un mes 34 millones de dólares.
Pero al margen de las ICOs, están naciendo numerosas plataformas para que abogados creen contratos inteligentes. Ya hemos mencionado el caso de Agrello, pero también tenemos la iniciativa suiza-norteamericana OpenLaw, basado en Ethereum y que incluso ofrece sus propias plantillas. Además, Smartcontract (que también permite la creación de contratos inteligentes) lanza próximamente su nueva funcionalidad LINK Network, pre-sale incluida, con la idea de resolver el problema de la interperabilidad entre cadenas de bloques. Sin olvidar a BlockCAT, otro servicio para crear y gestionar contratos inteligentes sin necesidad de saber programar y enfocado casi al usuario común.
«Accord Project», uno de los consorcios sobre contratos inteligentes
Por si esto no bastara, tenemos dos autodenominados consorcios en materia de contratos inteligentes para el mercado legal. Por un lado está Accord bajo Hyperledger de IBM y con varias compañías tecnológicas y firmas legales a la cabeza, como Cooley. Por otro lado tenemos el Global Legal Blockchain Consortium, con IBM Watson Legal presente y bajo una nueva plataforma blockchain llamada Integra Ledger, en principio especialmente pensada para el sector legal.
A todo ello hay que sumar que la semana pasada se incorporaron al Grupo de Trabajo de la Industria Legal de la Enterprise Ethereum Alliance, la versión de Ethereum por y para empresas, hasta 10 despachos de abogados (como por ejemplo Hogan Lovells) y varias facultades de Derecho (aquí la lista completa).
Y por si no hubiera suficiente, tenemos incluso una auditora de contratos inteligentes de la mano de Solidified.
Por tanto, ahora mismo tenemos tres grandes plataformas compitiendo en materia de contratos inteligentes para el sector legal, OpenLaw, Accord y el Global Legal Blockchain Consortium. A su vez, otras iniciativas más «particulares» como Agrello, Smartcontract o incluso Lawbot buscan su parte del pastel. Y todo ello sin olvidar la participación cada vez más activa de firmas legales en materia de blockchain como demuestran el caso de la Enterprise Ethereum Alliance y su grupo de trabajo específico y las iniciativas particulares de firmas como Linklaters, Deloitte o Seal.
Definitivamente algo se está moviendo en materia de blockchain, contratos inteligentes y sector legal.
Cuando hoy en día una herramienta legaltech avanzada describe las tecnologías o procesos aplicados, suele incluir alguno de los siguientes términos (o todos a la vez): procesamiento de lenguaje natural, machine learning (aprendizaje automático) y redes neuronales profundas. Todas ellas siempre enmarcadas en la idea de IA o Inteligencia Artificial.
Desde ese momento, y como si de un mantra de tratara, los términos son repetidos una y otra vez como elementos positivos y a destacar. Ahora bien, ¿qué significan y qué implican?
Si bien son términos que en parte pueden llegar a solaparse, vamos a ver a lo largo de varios posts cada uno de ellos, intentando explicar con cierto detalle cuál es su significado, qué problemas intentan resolver y cómo se están aplicando en el tratamiento de tareas legales.
Comenzaremos con el procesamiento de lenguaje natural o como dicen los anglosajones, «Natural Language Processing» (de ahora en adelante NLP).
El Procesamiento de Lenguaje Natural o NLP es el campo que estudia la comprensión y manipulación del lenguaje natural humano, es decir tal y como nos expresamos por escrito o de viva voz, por parte de un ordenador. Por ello trabaja áreas como el entendimiento por parte de una máquina del lenguaje humano, su percepción o generación. Por ejemplo, un software de traducción aplica NLP, siendo una de sus tareas entender que «Hello» es una palabra inglesa que en castellano se traduce como «Hola».
Como tantos otros conceptos, no es algo nuevo. De hecho, cuando Alan Turing formula por allá 1950 su famoso test en «Computing Machinery and Intelligence», está fijando las bases del NLP. Y es que si para pasar el test un humano no debe darse cuenta que está hablando con un programa de ordenador, es básico que la máquina entienda lo que le están diciendo.
El NLP, en mayor o menor grado de complejidad, se aplica a múltiples tareas de nuestro día a día, y desde hace bastantes años. Por ejemplo, y como ya se ha comentado, cualquier traducción de texto (por ejemplo un tuit) emplea NLP. De la misma forma, un sistema que extrae información de un email y partir de esos datos sugiere apuntar una cita en la agenda. También es NLP un análisis de sentimiento sobre si una expresión es positiva, negativa o neutra («Me encanta mi nuevo teléfono» vs «Mi nuevo teléfono va lento«). Igualmente usan NLP la clasificación de texto para detectar spam en el correo electrónico o la indicación de errores gramaticales mientras se escribe un texto.
¿Cómo intenta un ordenador analizar nuestras palabras y sus múltiples significados y variantes? Hay dos grandes corrientes: la simbólica y la estadística.
La aproximación simbólica consiste en un sistema de reglas del estilo «Si ocurre esto, haz eso», y hasta los años 80 fue la dominante bajo las teorías lingüísticas de Chomsky. Puede llegar a generar árboles de reglas realmente complejos, y para un humano resulta más sencillo de entender y predecir su comportamiento. La estadística es más moderna y explotó con la aparición de las técnicas de machine learning o aprendizaje automático y la abundancia de datos proporcionados por Internet. Muy simplificadamente, consiste en anotar y estructurar una serie de textos relacionados con la materia que nos interesa (por ejemplo, contratos de alquiler). Es decir, textos que el software puede comprender sin dificultad. A partir de esos primeros datos anotados, se crea un modelo estadístico al que se le comenzarán a proporcionar datos no anotados ni estructurados, que el algoritmo por su cuenta deberá comenzar a estructurar y clasificar de acuerdo a la información inicialmente suministrada. La base del modelo estadístico es que con suficientes datos previos, puede predecirse estadísticamente el tipo de palabras que se usarán en una frase. De modo que con relativamente menos trabajo, y muchos datos, se puede avanzar de forma más rápida y eficiente en una tarea como el NLP.
A día de hoy se usan casi por igual, incluso se combinan, aunque parece que el método estadístico se ha colocado a la cabeza.
Por otro lado, si alguien quiere profundizar en la materia, el siguiente vídeo de la Universidad de Stanford de introducción a un curso sobre NLP puede ser de gran ayuda. Además, muestra algunas de las tareas que el NLP ya entiende como resueltas, aquellas en las que todavía hay trabajo por hacer o las que aún son complejas para una máquina.
Course Introduction – Stanford NLP – Professor Dan Jurafsky & Chris Manning
Por ejemplo, son tareas casi resueltas la detección de spam, el etiquetaje de palabras (saber si lo leído es un verbo o un adjetivo) o el reconocimiento de nombres propios. Se progresa en conocer el sentido positivo, negativo o neutro de un texto, en deducir el significado de las palabras, la relación entre términos (por ejemplo que un «él» hace referencia a «Juan»), su traducción o la extracción de información. Ahora bien, todavía es difícil para una máquina responder una pregunta, parafrasear, hacer un resumen o mantener un diálogo en tiempo real.
Al final del día, el NLP intenta hacer comprensible el lenguaje humano para una máquina en 5 grandes áreas: la fonología, la morfología, la sintaxis, la semántica y la pragmática. Su archienemigo es la ambigüedad, algo de lo que el lenguaje humano está repleto. Ya sea por el uso de la ironía, el sarcasmo, los registros informales, los errores de pronunciación o escritura, los emojis, la mezcla de idiomas y tantas otras variantes que afectan al lenguaje humano escrito y hablado.
Por tanto, que una máquina sea capaz de comprendernos y dar respuesta no es tarea fácil todavía. Hay progresos obviamente importantes (véase el caso de asistentes inteligentes como Siri, Alexa, Google Now o Cortana). Pero todavía hay un camino largo por recorrer, especialmente cuando el software debe entender más allá de áreas o dominios muy concretos. De ahí que cuando un software señale que habla y entiende como un humano, ya que en su ficha técnica diga usar NLP, eso deba tomarse con una razonable reserva.
Dicho esto, ¿cómo afecta el procesamiento de lenguaje natural en tareas y textos legales?
Visto lo visto, y teniendo en cuenta que el Derecho es texto en su gran mayoría, parece que el sector legal es un caldo de cultivo ideal para aplicar técnicas de NLP y comenzar a automatizar los análisis, revisiones, extracción de información, y con el tiempo, los resúmenes y generación de nuevo texto.
De hecho, proyectos a nivel europeo como MIREL usan NLP para la creación internacional de un marco formal de trabajo en el minado y comprensión de textos legales. La facultad de Derecho de Harvard ha digitalizado toda su base de jurisprudencia, la mayor de EE.UU. junto a la de la Biblioteca del Congreso de EE.UU. Y en materia de términos y condiciones tenemos proyectos como Usable Privacy, que usando NLP analiza la estructura de políticas de privacidad para facilitar al usuario la detección de las áreas que más le importan.
Sin embargo, en realidadel lenguaje humano legal o «legalés» tiene complejidades bastante particulares: la sintaxis legal es enrevesada y poco natural, se usan frases mucho más largas (entre 20 y 25 palabras más de media que en un periódico, por ejemplo), hay un mayor número de preposiciones pero un menor número de verbos o adverbios, se usan múltiples complementos encadenados y frases subordinadas, lo que hace que existan vínculos entre palabras o frases muy separadas. Además, muchos de los términos legales usados solo tienen sentido en el ámbito jurídico, sin existir una correlación en el lenguaje natural común.
En todo caso, el «legalés» presenta aspectos favorables como su estructura rígida o el uso de una terminología bastante común. Para más detalles sobre la aplicación de NLP en textos legales, aquí un buen trabajo (en inglés).
Natural Language Processing and Legal Knowledge Extraction – Simonetta Montemagni, Giula Venturi
Por tanto, aplicar NLP a textos legales implica unos esfuerzos concretos, no es una tarea tan sencilla como aplicar los métodos del lenguaje natural común al «legalés», pero en cualquier caso no es una barrera insuperable. De hecho, en la actualidad las herramientas avanzadas de legaltech usan el NLP y lo hacen mayormente para dos tareas:
1.- Recuperar información
El Information Retrieval o Recuperación de Información consiste en la ciencia de buscar información o metadatos en un documento o incluso buscar documentos en sí en múltiples y variados repositorios.
Las herramientas de e-Discovery o descubrimiento electrónico son los grandes avanzados en esta materia. El e-Discovery no es más que la búsqueda, localización aseguración y examen de datos o documentos electrónicos con la intención de usarlos como evidencia en un caso. Por tanto, ayudan a que una firma legal descubra entre miles de documentos los que pueden ser relevantes en un asunto.
Esa búsqueda podría hacerse por frases o palabras clave, pero el NLP ayuda a hacerla mediante conceptos. De modo que si se buscan documentos que incluyan el término «pago», el software muestra los que mencionan «pago» expresamente pero también los que incluyen conceptos relacionados como facturas, presupuestos, tarifas, honorarios o indemnizaciones, aunque no incluya en término «pago». La cuestión es que el software entiende que aunque esos documentos no incluyen el término «pago», están vinculados al mismo. Y eso es gracias al NLP.
Las herramientas de e-Discovery son mucho más populares en el mercado anglosajón, debido a algunas particularidades legales. Entre ellas destacan software como Brainspace, Relativity o Everlaw, entre otras.
2.- Extraer información
El Information Extraction o Extracción de Información consiste en la tarea de extraer automáticamente información estructurada de documentos desestructurados o semiestructurados. Es decir, sacar datos útiles y ordenados de textos en principio no preparados para ser «entendidos» por una máquina.
Como hemos visto antes, es una de las áreas en las que se está progresando más en materia de NLP.
Ésta sea seguramente el área en la que más están trabajando muchas de las herramientas legaltech más conocidas. Ya sea las que se encargan de revisar contratos para detectar cláusulas inaceptables o requeridas (como hace LawGeex), ayudar en los procesos de due dilligence a detectar plazos, obligaciones o vigencias a tener en cuenta (como hace Luminance)o analizar jurisprudencia para extraer información relevante para plantear una estrategia procesal, según el histórico de resoluciones de un concreto juez, por ejemplo (como hace Ravel Law).
Luego esta información se usa para generar informes, crear visualizaciones a vista de pájaro de un gran conjunto de documentos o ayudar en la preparación de un asunto. Lo que al final del día ayuda al profesional a tomar mejores decisiones.
Obviamente estas técnicas no se emplean de forma independiente, sino que se combinan y se unen a otras como la semántica y la pragmática, o lo que es lo mismo, intentar que el software sea capaz de «entender» el texto y comprender el contexto en el que tiene lugar. Por ejemplo, resumiendo un texto a partir de la «lectura» de varios documentos, y creando de forma abstracta un texto nuevo (no usando por tanto las frases más destacadas de cada texto). Sin embargo, ésta es una de las tareas que todavía resulta compleja para un software, si bien es una simple cuestión de tiempo llegar a ello.
En conclusión, el Procesamiento de Lenguaje Natural o NLP consigue que las máquinas puedan entender, manipular y generar textos a partir del lenguaje humano, escrito o verbal. Se aplica en ámbitos comunes del día a día o en áreas y sectores específicos, como el legal. Dado que el Derecho es mayoritariamente texto, incluso con sus particularidades, la legaltech está haciendo cada vez mayor uso y análisis de esos textos, aumentando las capacidades del profesional (que ahorrará tiempo y ganará en eficiencia). Ahora bien, eso le obliga a centrarse cada vez más en tareas de mayor valor ya que el software se va encargando de las más rutinarias y comunes.
Por lo tanto, no se trata de si el procesamiento de lenguaje natural se va a aplicar o no al sector legal (, de hecho, ya se está aplicando). Se trata de cuándo será eso una práctica común en el día a día jurídico, y eso es una simple cuestión de tiempo.